在日常的分类任务中,「数据类别不平衡」是一个很常见的问题,如果对其不加关注,则可能会严重影响模型性能。
对于「类别不平衡」这一问题,通常可以从三个角度入手,即「数据」、「模型」以及「评价指标」,本文将对这三个角度进行介绍。
一、数据
1.1 扩大数据集
数据集类别不平衡,最直接的想法就是尽可能地增加数据(主要关注小样本数据),或许增加数据后分布就会变得平衡。
1.2 对大类欠采样
若数据集已经固定,则我们可以考虑随机去除大类中的一些数据,以此达到类别平衡的目的。
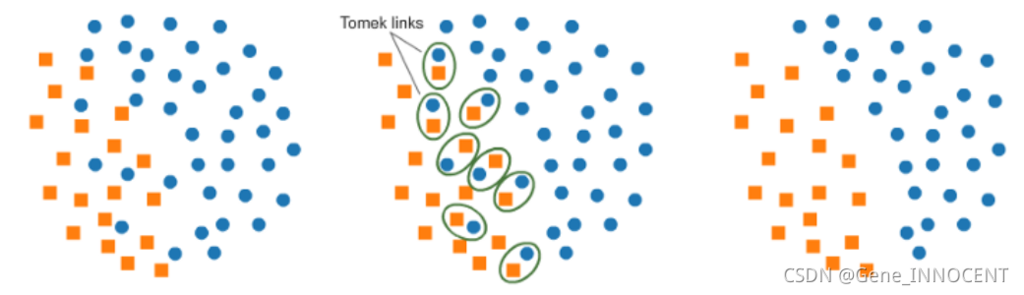
常见的算法有 Tomek links,如下图所示,该算法找到数据集中非常接近的一个不同类别的点对,并删除其中的大类样本。
另外,还有一种名为 EasyEnsemble 的算法,其在实际应用上表现良好。具体思路是:执行 $n$ 次,每次从大类中随机选出一部分,使其数量与小类总数一致,对其训练得到 $f_i$,最后将 $n$ 个模型集成起来得到最终模型。
1.3 对小类过采样
为使类别平衡,除了让多的变少,也可以让少的变多。在无法收集更多数据的情况下,我们可以考虑人为构造小类数据。
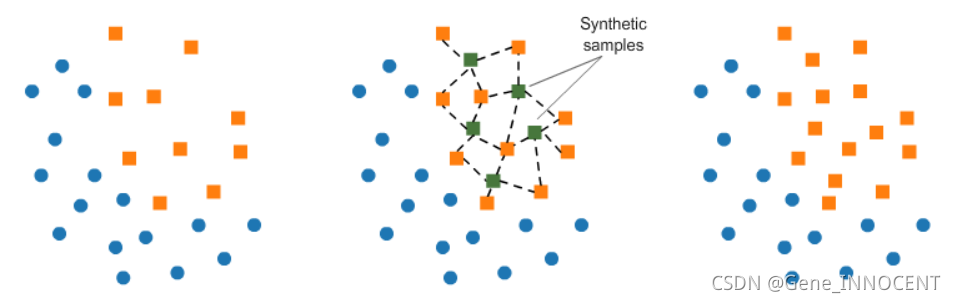
常见的算法有 SMOTE,如下图所示,该算法随机找到一个小类点 x,再在其最近的 k 个小类点中随机选出 y,在 x 和 y 的连线上随机生成一个人造小类数据。
二、模型
除了可以对数据集进行修正,我们也可以对模型训练或预测的过程进行更改,使其匹配类别不平衡的环境。
2.1 模型训练过程
首先很直接的想法是更换模型,例如采用决策树以及基于树集成的算法(Random Forest、Gradient Boosted Trees 等),这些算法不会对小类数据进行忽略,以此对类别不平衡的环境进行匹配。
其次我们可以考虑在训练过程中,对不同类别的数据赋予不同的权重,如对小类数据赋予更大的权重,以此迫使模型对小类数据加以关注。
最后我们也可以更换训练视角,从考虑分类任务转变为对异常数据进行检测,即将小类数据视为异常点。
2.2 模型预测过程
假设模型输出 $y\in[0,1]$,当类别平衡时,$\displaystyle\frac{y}{1-y}>1$ 即为正例;因此当类别不平衡时,可以根据
来进行正例判别,其中 $m^{+}$、$m^-$ 分别表示正例、反例样本的数量。
三、评价指标
最后,面对类别不平衡问题,常见的 Accuracy 衡量标准不再适用,可以考虑如下一些新的评价指标:
-
混淆矩阵(Confusion Matrix)
-
准确率(Precision)、召回率(Recall)、F1-Score
-
ROC 曲线面积