一、回归
在回归任务上,目前最常用的性能度量方式是均方误差 (Mean Squared Error, $\text{MSE}$):
其余还有均方根误差 (Root Mean Squared Error, $\text{RMSE}$):
平均绝对误差 (Mean Absolute Error, $\text{MAE}$):
平均绝对百分比误差 (Mean Absolute Percentage Error, $\text{MAPE}$):
对称平均绝对百分比误差 (Symmetric Mean Absolute Percentage Error, $\text{SMAPE}$):
加权平均绝对百分比误差 (Weighted Mean Absolute Percentage Error, $\text{WMAPE}$):
$\text{R-squared}$ 又称决定系数 (Coefficient of Determination),在统计学中用于度量因变量的变异中可由自变量解释部分所占的比例,以此来判断回归模型的解释力:
该数值越大越好,但当数据分布方差较大时,即使预测不准,$\text{R}^2$ 依然较大,此时该评价指标效果就不太好。
二、分类
在分类任务上,最常用的性能度量方式是错误率 (Error Rate, $\text{Err}$) 与精度 (Accuracy, $\text{Acc}$),其同时适用于二分类与多分类:
2.1 二分类
2.1.1 P-R 曲线
在信息检索、Web 搜索等应用中,我们会更关心查准率、查全率等相关指标,由此引出混淆矩阵 (Confusion Matrix),具体定义如下所示:
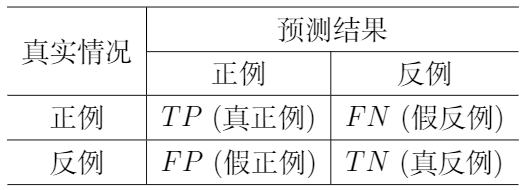
依据混淆矩阵,我们可以定义查准率 (Precision, $\text{P}$)、查全率 (Recall, $\text{R}$):
当分类器的置信度不同时,其对应的 $\text{P}$ 与 $\text{R}$ 也会发生变化,因此很自然地可以引出 $\text{P-R}$ 曲线,其中横轴为查全率,纵轴为查准率,而平衡点 (Break-Even Point, $\text{BEP}$) 即为 $\text{P} = \text{R}$ 时的取值。
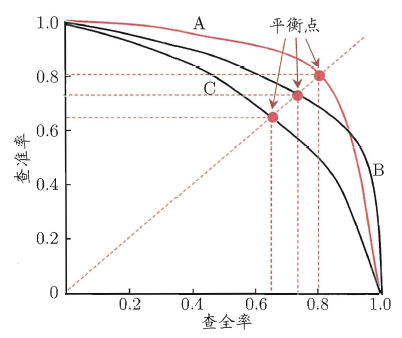
进一步地,我们可以对 $\text{P}$、$\text{R}$ 进行加权,即定义 $\text{F}1\text{-}score$ ($\text{F}1$)、$\text{F}\beta$-score ($\text{F}\beta$),其中 $\beta>0$ 度量了查全率对查准率的相对重要性,当 $\beta>1$ 时查全率有更大影响,当 $\beta<1$ 时查准率有更大影响。
2.1.2 ROC 曲线
在许多关注排序本身质量的应用中,$\text{AUC}$ (Area Under ROC Curve) 是一种常见的指标,其数值为 ROC 曲线下的面积。ROC 曲线以假正例率 (False Positive Rate, $\text{FPR}$) 为横轴,以真正例率 (True Positive Rate, $\text{TPR}$, 等价于召回率 $\text{R}$) 为纵轴,如下所示:
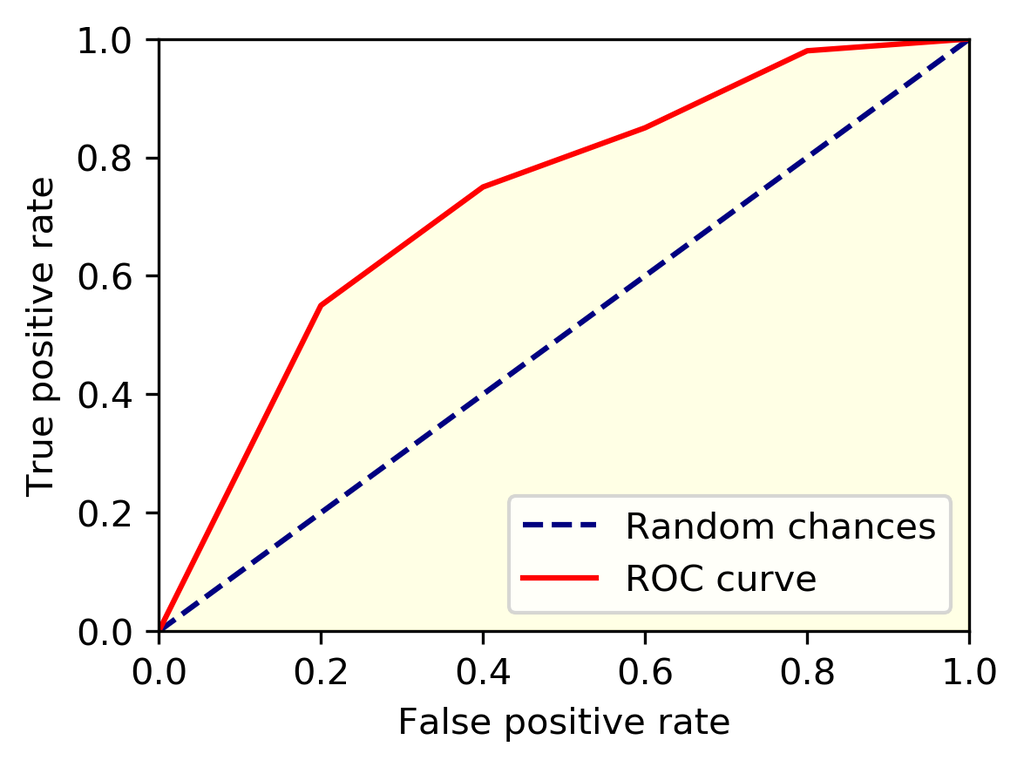
计算上述 ROC 曲线下的面积,即可得到 $\text{AUC}$,其物理意义为「一个随机正样本,其排序位置高于一个随机负样本的概率」,具体计算过程如下:
2.2 多分类
在多分类任务上,通常会对应 $n$ 个混淆矩阵,此时可以直接对各混淆矩阵求均值,定义宏查准率 ($\text{macro-P}$)、宏查全率 ($\text{macro-R}$) 以及宏 $\text{F}1$ ($\text{macro-F}1$):
也可以先对混淆矩阵中各元素求平均,得到 $\text{TP}$、$\text{FP}$、$\text{TN}$、$\text{FN}$ 的均值 $\overline{\text{TP}}$、$\overline{\text{FP}}$、$\overline{\text{TN}}$、$\overline{\text{FN}}$,进而定义微查准率 ($\text{micro-P}$)、微查全率 ($\text{micro-R}$)、微 $\text{F}1$ ($\text{micro-F}1$):
2.3 多标签
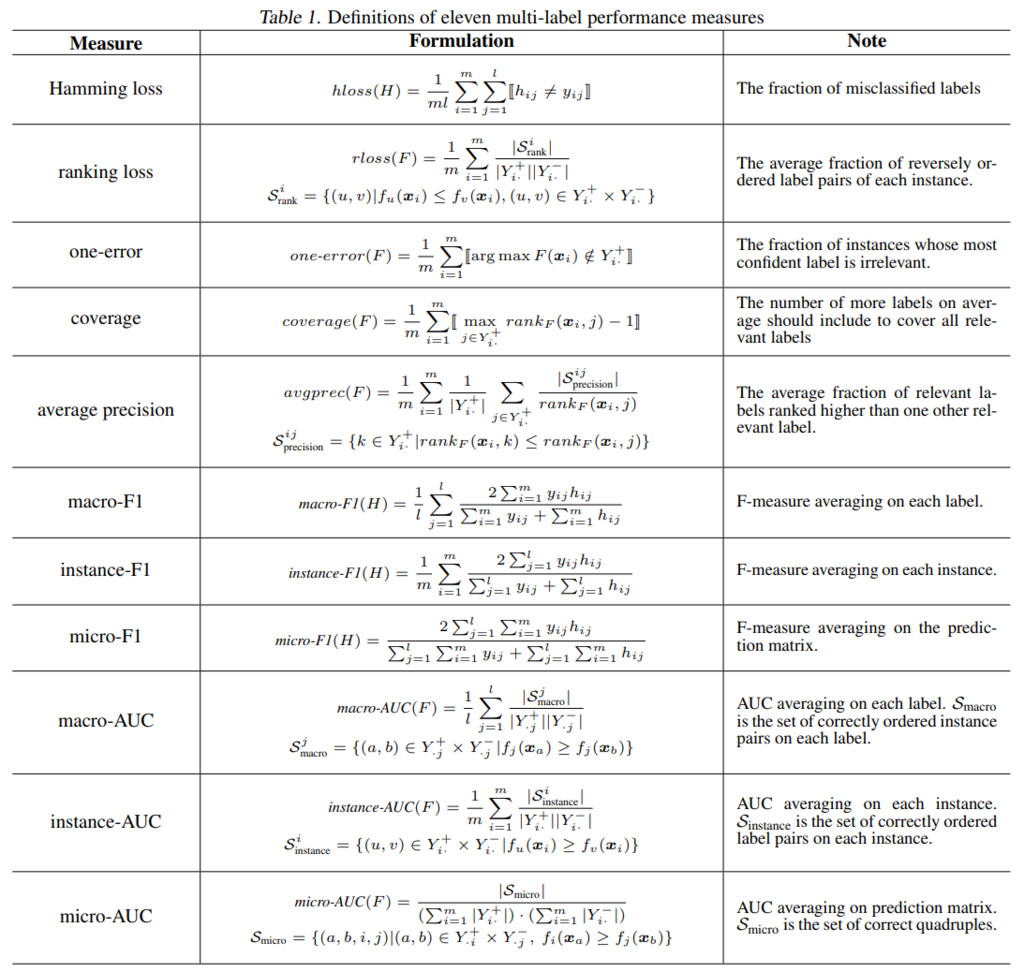
上图来自 [ICML17 - X.-Z. Wu],其中 $y_{ij}$ 表示第 $i$ 个样本的第 $j$ 个标签,$Y_{i .}^{+}=\{j \mid y_{i j}=1\}$ 表示第 $i$ 个样本中的正类标签,$Y_{\cdot j}^{+}=\{i \mid y_{i j}=1\}$ 表示第 $j$ 个标签为正的样本。
三、排序
该部分性能度量主要与排序有关,在信息检索、推荐系统中经常使用。
3.1 F-measure
首先是 $\text{Precision}@k$ 与 $\text{Recall}@k$,在其计算中,分子均为前 $k$ 个搜索结果中相关结果的个数,但在分母上,前者为 $k$,后者则为总的相关结果个数。举个例子,假设现在搜索结果为 $[1 \ 2\ 3\ 4\ 5]$,其中 $[1\ 3\ 5]$ 为相关文档,则:
由此可以直接引出 $\text{F}_\beta @k$:
3.2 MAP
$\text{MAP}$ (Mean Average Precision) 在排序任务中使用较多,其计算主要与 $\text{P}$、$\text{R}$ 有关。首先我们需要定义 $\text{AP}$ (Average Precision):
其中 $n$ 表示「搜索结果总数」,$m$ 表示「相关结果总数」,$\text{P}(k)$ 表示 $\text{Precision}@k$,$rel(k)$ 则表示第 $k$ 个搜索结果是否相关,相关为 1,否则为 0。仍使用上述例子举例,则可以得到:
至此,可以很自然的引出 $\text{MAP}$,即 $\text{AP}$ 的平均值,其定义如下:
其中 $Q$ 表示查询的总数,$AP_i$ 表示第 $i$ 次查询的 $\text{AP}$ 值。
3.3 MRR
$\text{MRR}$ (Mean Reciprocal Rank) 即第一个相关结果排名的倒数的均值,定义如下:
其中 $rank_i$ 即为第 $i$ 个查询的第一个相关结果的排名。
3.4 ERR
$\text{ERR}$ (Expected Reciprocal Rank) 即用户需求被满足时停止位置的倒数的期望。相比于 $\text{MRR}$,$\text{ERR}$ 认为用户按顺序从高到低依次查看文档,一旦某个文档满足了用户的需求,则停止查看后续文档,即更加关注用户停止的位置。
为了引出 $\text{ERR}$,我们首先定义用户在位置 $r$ 停止的概率:
其中 $R_i=\mathcal{R}(g_i)$,$g_i$ 是第 $i$ 个文档的相关度等级,而 $\mathcal{R}(\cdot)$ 则是「文档相关度等级」到「用户停止概率」的映射,其定义如下:
举个例子,我们可以令 $g=0$ 表示文档不相关,而 $g=g_{\max}=5$ 表示文档相关度最大。至此,我们可以对 $\text{ERR}$ 进行定义:
其中 $n$ 为搜索结果总数,而 $\varphi(\cdot)$ 可以为任意满足 $\varphi(1)=1$ 且 $\varphi(r)\rightarrow0\text{ as }r\rightarrow +\infty$ 的函数形式,例如 $\varphi(r)=\frac{1}{\log_2(r+1)}$。
3.5 NDCG
与 $\text{ERR}$ 的计算过程一致,$\text{nDCG}$ 计算时也会对文档相关度分多个等级。
3.5.1 CG
$\text{CG}$ (Cumulative Gain) 表示前 $k$ 个文档相关度总和:
其中 $rel_i$ 表示第 $i$ 个文档的相关度等级,例如 $[-1\ 0\ 1\ 2]$ 分别表示 $[$垃圾 无关 相关 非常相关$]$。
3.5.2 DCG
$\text{DCG}$ (Discounted Cumulative Gain) 是对 $\text{CG}$ 的进一步改进,在其基础上为每个位置赋予了不同的权重:
除上式外,也可以修改文档相关度的表达式,得到下述版本:
3.5.3 IDCG
$\text{IDCG}$ (Ideal DCG) 表示理想情况下的 $\text{DCG}$,即将前 $k$ 个文档根据相关度从大到小排序,得到 $\text{DCG}$ 的理想值。而 $\text{NDCG}$ 则是用 $\text{IDCG}$ 对 $\text{DCG}$ 进行归一化的结果:
由于每个查询语句检索到的结果文档个数不同,因此直接使用 $\text{DCG}$ 进行比较并不恰当,因此需要对 $\text{DCG}$ 进行归一化处理,得到 $\text{NDCG}$ 后再进行比较。