CLIP (Contrastive Language-Image Pre-training) 方法,使用大规模数据 (4 亿图像文本对) + 大模型 (Vit Large),得到了性能超强的预训练模型。
通过将文本作为监督信号,得到了图像下异构输出空间的各类任务的统一预训练模型。
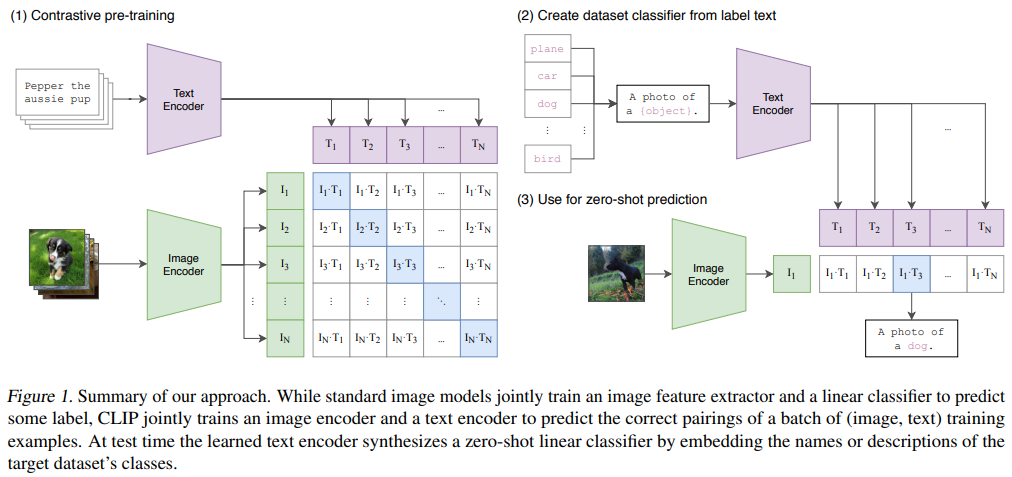
一、CLIP 方法概述
预训练模型
OpenAI 使用 4 亿对「文字-图像」通过对比学习,得到预训练模型。
具体来说,将一个 batch 的「Text-Image pair」 分别输入 Text Encoder 和 Image Encoder,再两两组合,即可得到一个 batch_size*batch_size 的矩阵,其中对角线为正样本,其余为负样本,即可使用对比学习的损失对模型进行训练。
Zero-shot 推理
以 ImageNet 的分类任务为例,将所有的类别通过 A photo of a [object] 的模板转成文字,再分别通过 Text Encoder 得到文本向量,与图像向量计算余弦相似度,即可完成推理。
训练伪代码
CLIP 论文中给出的伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
其中 $t$ 为可学的温度参数,用于修改 logits 分布。在上述代码中,其越小,logits 分布中的数值就会都变小,经过指数运算后,变得更小,使得分布更平滑,对于所有负样本一视同仁;其越大,logits 分布中的数值就会相应变大,使得分布更集中,更 peak,模型越会关注困难的负样本,但它们可能是潜在的正样本,导致模型难收敛或泛化差。
此处需要注意,之前的温度系数通常是一个超参数,但此处由于数据集过大,不便于调参,因此直接将其当作了可学的参数。
下面给出计算 loss 的具体代码,首先是 CLIP 模型的 forward 函数 (model.py):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
具体计算损失的部分 (train.py):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import torch.nn.functional as F
with torch.no_grad():
for i, batch in enumerate(dataloader):
images, texts = batch
images = images.to(device=device, dtype=input_dtype, non_blocking=True)
texts = texts.to(device=device, non_blocking=True)
with autocast():
model_out = model(images, texts)
image_features = model_out["image_features"]
text_features = model_out["text_features"]
logit_scale = model_out["logit_scale"]
# features are accumulated in CPU tensors, otherwise GPU memory exhausted quickly
# however, system RAM is easily exceeded and compute time becomes problematic
all_image_features.append(image_features.cpu())
all_text_features.append(text_features.cpu())
logit_scale = logit_scale.mean()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
batch_size = images.shape[0]
labels = torch.arange(batch_size, device=device).long()
total_loss = (
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
其中 F.cross_entropy 的实现较为复杂,但原理比较简单,其结果与下述代码等同:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import torch
import numpy as np
import torch.nn.functional as F
def log_softmax(logits, dim):
exp_logits = torch.exp(logits)
softmax = exp_logits / exp_logits.sum(dim=dim, keepdim=True)
return torch.log(softmax)
def cross_entropy_loss(logits, labels):
log_probs = log_softmax(logits, dim=1)
return torch.mean(-log_probs[torch.arange(log_probs.shape[0]), labels])
if __name__ == "__main__":
logits = torch.Tensor([
[1.9269, 1.4873, 0.9007, -2.1055],
[3.9269, 5.4873, 4.9007, -1.1055]
])
labels = torch.arange(2)
print(cross_entropy_loss(logits, labels))
print(F.cross_entropy(logits, labels))
工程细节
-
minibatch size 为 32,768;
-
模型训练使用了 Mixed-precision (Micikevicius et al., 2017),加速训练 + 节省 memory;
-
为进一步节省 memory,使用了 gradient checkpointing (Griewank & Walther, 2000; Chen et al., 2016)、half-precision Adam statistics (Dhariwal et al., 2020) 以及 half-precision stochastically rounded text encoder weights;
-
训练时间:The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
推荐博文:如何在多个 GPU 上训练大模型?
二、实验分析
-
在 ImageNet 上,使用 zero-shot 的方式,达到了 ResNet-50 的效果 (76.2%);
- CLIP 推理时,类别的 prompt 为一句话时效果更好,一个单词容易有歧义性,且模型训练时 Text 也为句子(Prompt Engineering);
- 更加细化 prompt,可以得到更好的结果,例如「A photo of a {label}, a type of pet.」
- Prompt Ensemble:使用 80 个 prompt 模板,并集成所有的推理结果(Prompt 模板)
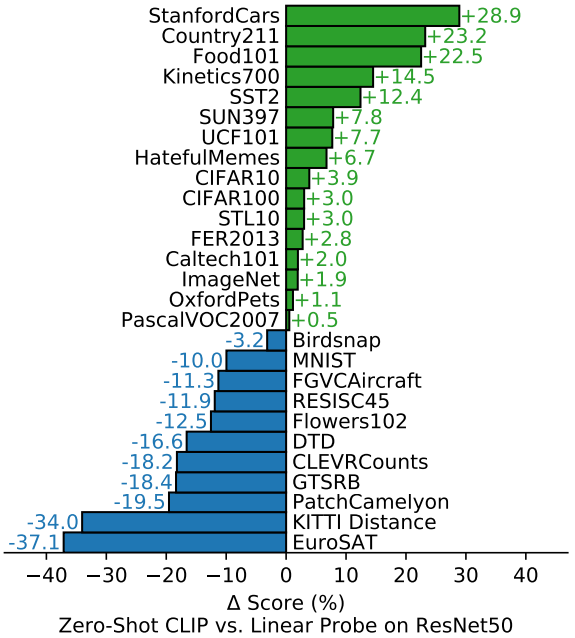
- Zero-shot CLIP 与「ResNet50 + 最后一层微调」的方式对比(绿色为 CLIP 胜出):
- DTD(图片纹理分类)、CLEVRCounts(给图片中物体计数)
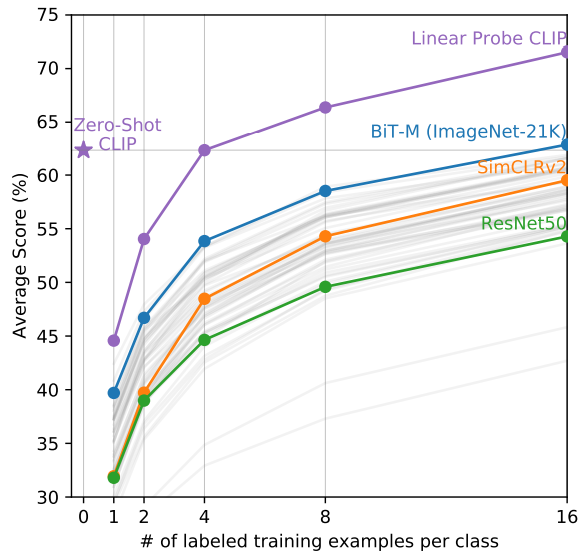
- Few-shot CLIP 与一些 Few-shot 方法的比较:
- Linear Probe:把模型冻住,再在上面加一些分类头
三、CLIP 后续的各类应用
StyleCLIP:根据文字修改图片

CLIPDraw:根据文字生成简笔画

ViLD:目标检测,检测通过文字给出的新类别

clifs:根据文字在视频中寻找关键帧
四、Limitation
-
通过「扩大数据集 + 扩大模型规模」的方式,让 CLIP 在所有任务上打败 SOTA,代价过高,且不现实;
-
在很多细粒度(fine-grained)的分类任务上,和一些更加抽象的任务上(数图片中物体个数),CLIP 并不如 ResNet-50 的效果,甚至可能是瞎猜;
-
在 MNIST 上只有 88% 的准确率(4 亿张图片中并不包括 MNIST 这类图片);
-
在某些任务上,One-shot 的结果甚至比 Zero-shot 的效果更差。
五、Practice
安装 CLIP:
1
2
3
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
测试图片:

测试代码:
- 效果确实不错,没有被黄皮耗子干扰()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import time
import clip
import torch
import numpy as np
from PIL import Image
labels = [
"A photo of a Pikachu",
"A photo of yellow",
"A photo of Pokémon",
"A photo of a yellow mouse with a tail",
"A photo of a milky way",
"A photo of a blue sky",
"A photo of a blue sea",
"A photo of yellow stars",
"A photo of black stones"
]
start_time = time.time()
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-L/14")
print(f"Model loading time: {time.time() - start_time}s")
start_time = time.time()
image = preprocess(Image.open("pikachu.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(labels).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print(f"Inference time for a image: {time.time() - start_time}s")
probs = probs.astype(float).reshape(-1).tolist()
for prob, label in zip(probs, labels):
print(f"Label probs: {prob}, label: {label}")
输出结果:
1
2
3
4
5
6
7
8
9
10
11
Model loading time: 42.73839998245239s
Inference time for a image: 4.575920820236206s
Label probs: 0.822265625, label: A photo of a Pikachu
Label probs: 0.007572174072265625, label: A photo of yellow
Label probs: 0.09368896484375, label: A photo of Pokémon
Label probs: 0.005123138427734375, label: A photo of a yellow mouse with a tail
Label probs: 6.252527236938477e-05, label: A photo of a milky way
Label probs: 0.0003380775451660156, label: A photo of a blue sky
Label probs: 0.00018668174743652344, label: A photo of a blue sea
Label probs: 0.07073974609375, label: A photo of yellow stars
Label probs: 3.5762786865234375e-07, label: A photo of black stones
输出结果:
1
2
3
4
5
6
7
8
9
10
11
Model loading time: 42.73839998245239s
Inference time for a image: 4.575920820236206s
Label probs: 0.822265625, label: A photo of a Pikachu
Label probs: 0.007572174072265625, label: A photo of yellow
Label probs: 0.09368896484375, label: A photo of Pokémon
Label probs: 0.005123138427734375, label: A photo of a yellow mouse with a tail
Label probs: 6.252527236938477e-05, label: A photo of a milky way
Label probs: 0.0003380775451660156, label: A photo of a blue sky
Label probs: 0.00018668174743652344, label: A photo of a blue sea
Label probs: 0.07073974609375, label: A photo of yellow stars
Label probs: 3.5762786865234375e-07, label: A photo of black stones
参考资料
-
ICML21 - CLIP: Learning Transferable Visual Models From Natural Language Supervision
-
ICCV21 - StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
-
NIPS22 - CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders
-
ICLR22 - ViLD: Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation