该篇 Tutorial 主要对 Model Reuse 当下的进展进行了整理和总结。
The Paradigm Shifts
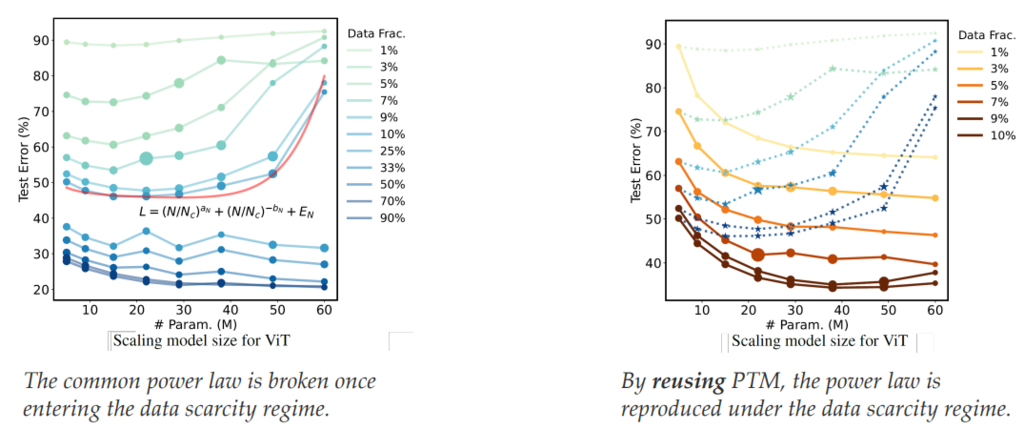
Tutorial 中指出在一些数据量比较稀少的场景,neural scaling law (the performance, training data, and model size generally should follow a power law) 不一定成立,但复用 PTM 依然能复现出所期待的曲线 [Wang et al., ICML’23]:
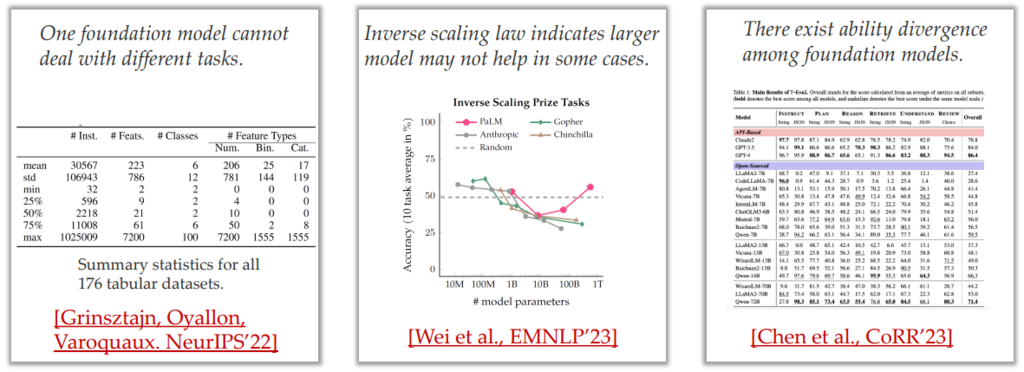
但实现一个基础的 PTM,将其运用在各种任务上并不现实:
-
例如在表格场景中,无法使用一个模型解决各种各样的任务 [Grinsztajn et al., NeurIPS’22]
-
此外在某些场景下,一味地扩大模型参数可能会导致性能下降 [Wei et al., EMNLP’23]
-
并且使用不同的 PTM 复用,得到的效果也差距很大 [Chen et al, CoRR’23]
基于上述观察,Tutorial 中指出当前的范式已发生变化:
- 从「Learning from Data」转变为了「Learning from Data and PTMs」
Will Model Reuse Always Help?
我们所期望出现的曲线图如下:
-
当本地数据比较小的时候,PTM 的帮助比较大;
-
当本地数据比较多的时候,PTM 依然有帮助。
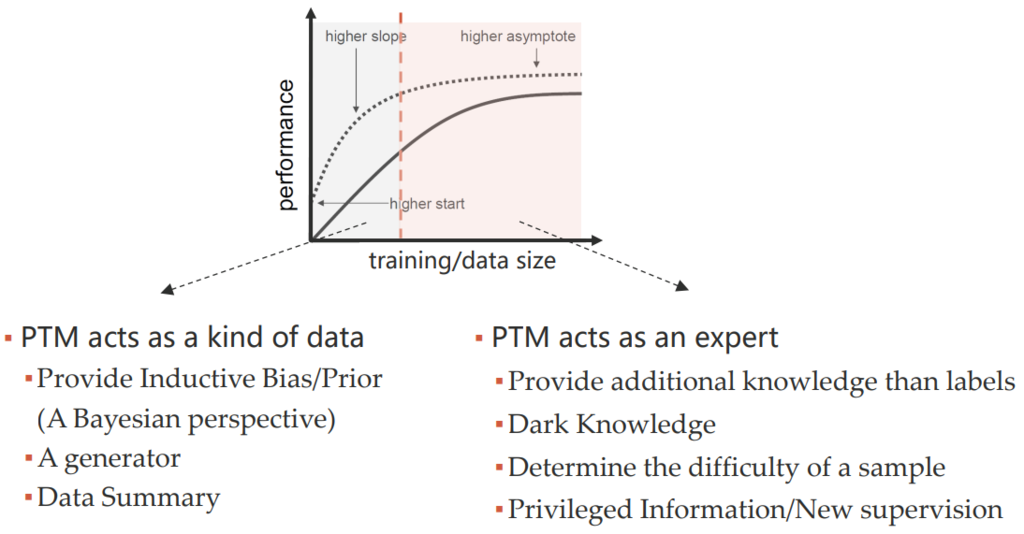
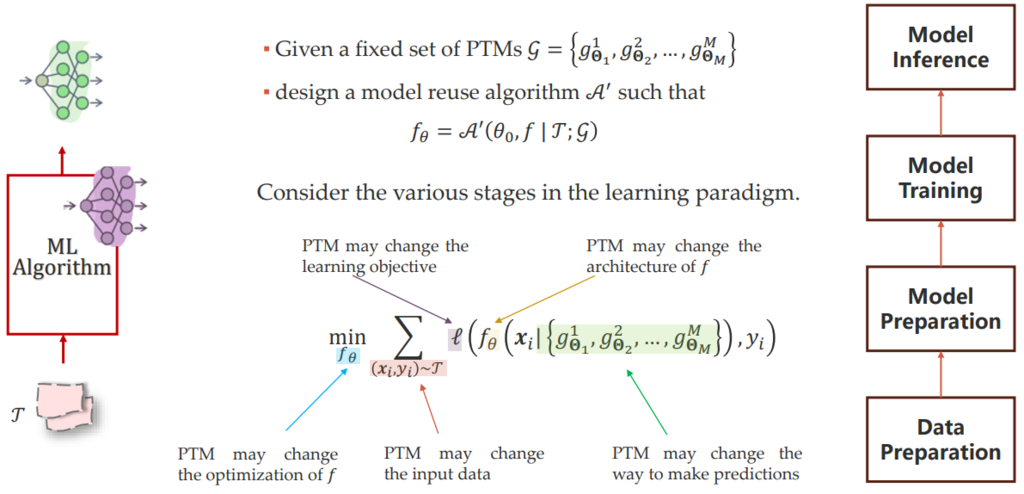
PTM 可能对整个训练过程带来的影响如下:
-
改变训练目标(例如,知识蒸馏,将目标模型与 PTM 的输出差异作为正则项);
-
改变目标模型结构(例如,在 PTM 的基础上,增加新的模块);
-
改变目标模型的优化过程(例如,将 PTM 的 weight 作为新模型的初始化);
-
改变最终数据预测的方式(例如,将新模型和 PTM 的输出做集成);
-
改变目标模型的输入数据(例如,将 PTM 的输出拼接至原数据)。
具体的一些方式总结如下:
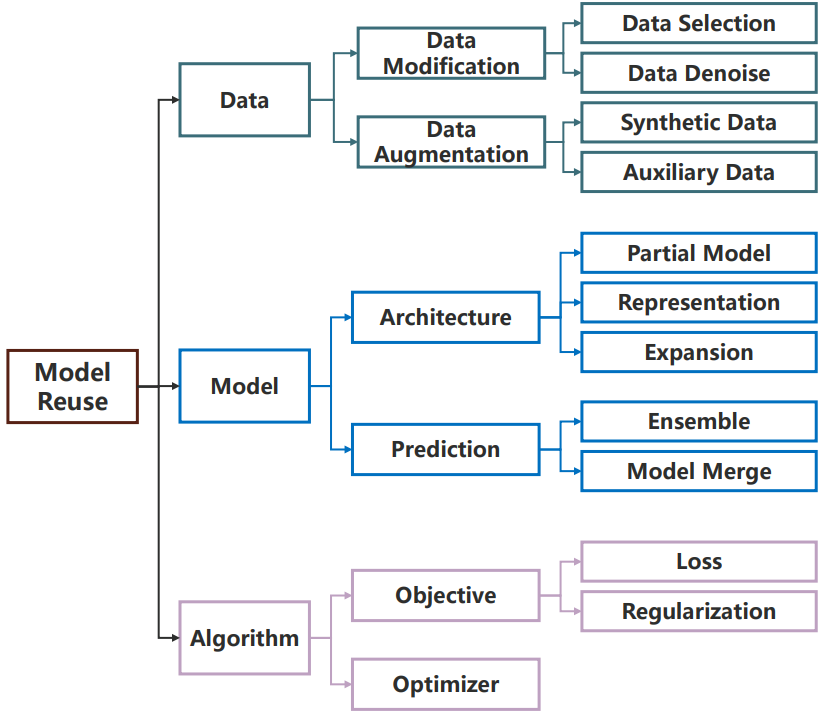
Methods for Reusing Pre-Trained Models
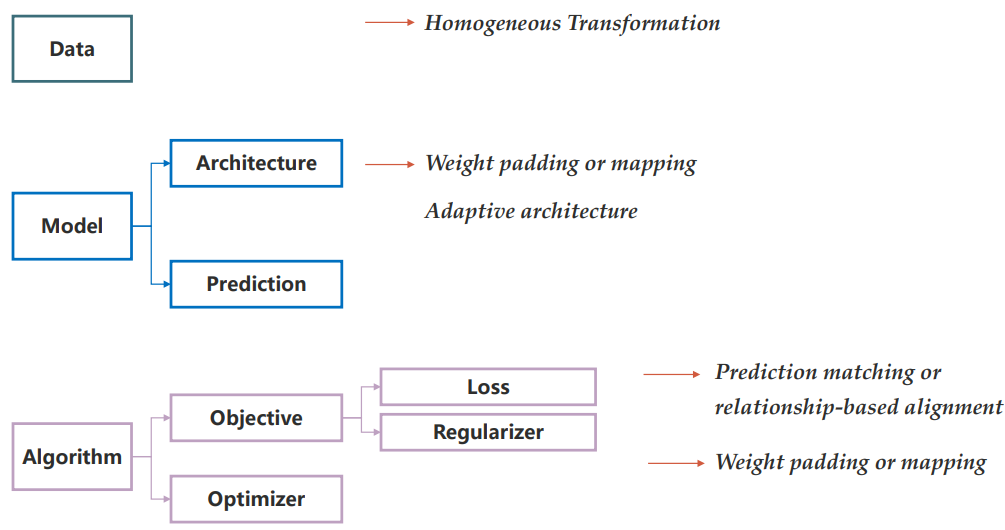
模型复用可以从多个角度进行分类:(1)同构模型复用和异构模型复用;(2)单模型复用和多模型复用;(3)从 data-level、model-level 和 algorithm-level 进行模型复用。
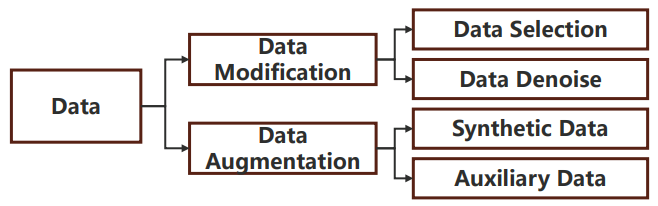
Data Level
在数据层面,PTM 可以为目标任务生成更丰富的数据,也可以过滤一些噪声数据,具体分类如下:
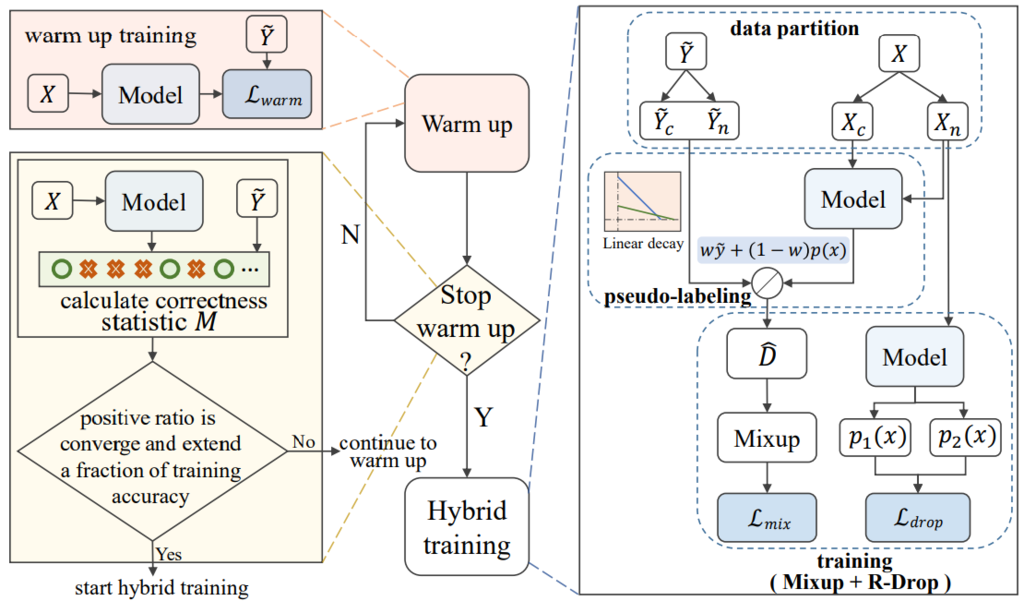
Data Denoise [Cheng et al., EMNLP’23]:其假设在训练过程中,噪声数据更难学且噪声数据的预测标签更不稳定;基于此,其通过 warm-up 的训练将目标数据分为了 clean data 和 noisy data,并给其打上了新的 pseudo-label;最后,其通过 mix up 的方式再次训练整个模型,即对使用 PTM 得到的 embedding 数据进行线性组合,构造了新的训练数据。
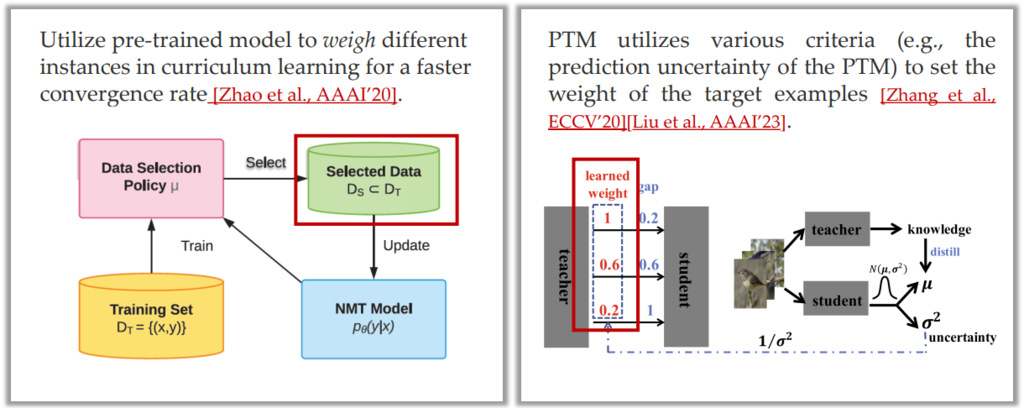
Data Selection [Zhang et al., ECCV’20] [Liu et al., AAAI’23]:使用 PTM 对样本的置信度,挑选数据或对数据加权。
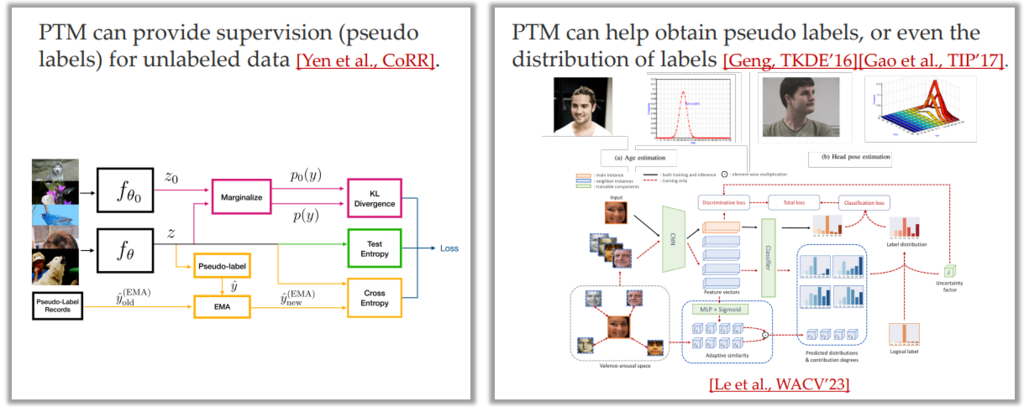
PTM for Richer Labels:使用 PTM 为无标记数据打 pseudo label;使用 PTM 获取 label 的分布 [Le et al., WACV’23]。
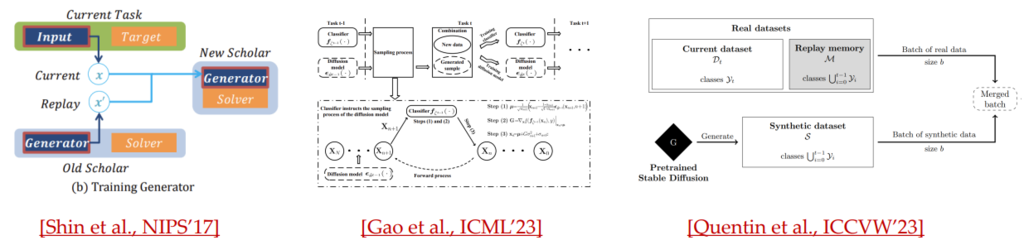
PTM for Data Augmentation:使用 GAN / SD 等技术用于数据生成。
Model Level
从模型层面出发,PTM 通常有多种局部复用的方式:
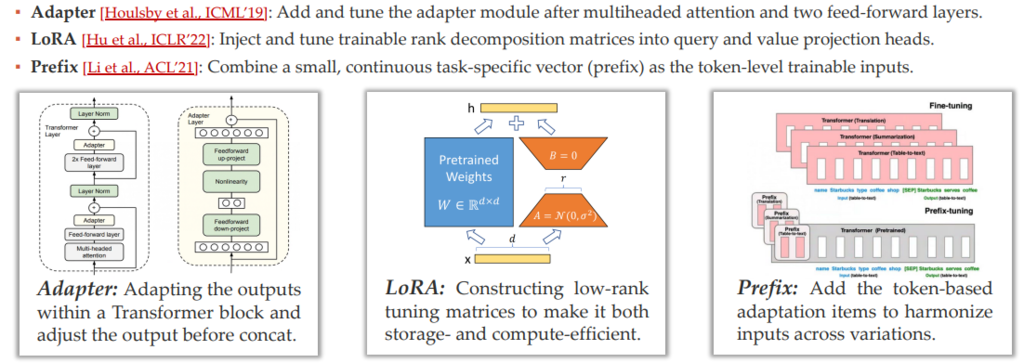
Tuning Partial Weights:
-
Partial-K [Jia et al., ECCV’22]: Tune the top-k layers of a PTM.
-
Scale and Shift [Lian et al., NeurIPS’22]: tune the scale and shift parameters of the PTM.
-
BitFit [Ben-Zaken et al., ACL’22] : tune (a subset of) bias-terms of the PTM.
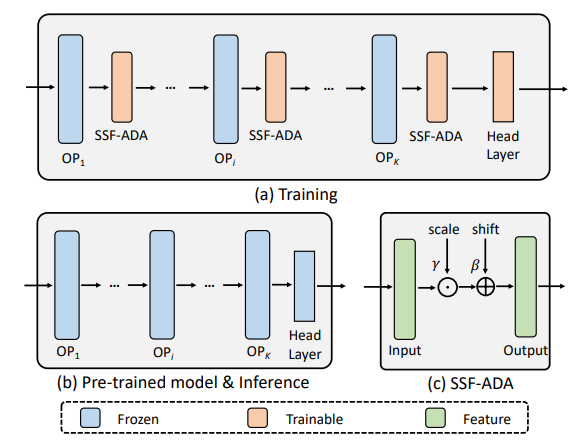
Tuning Add-ins: : adding extra structure and reusing the existed pretrained knowledge with the original parameters remain fixed.
Reuse PTM for Model Prediction:
-
Ensemble: Logit or probability ensemble (Need to consider the calibration issue)
-
Model merge: Average the weight of two homogeneous models [Singh and Jaggi et al., NIPS’20].

Algorithm Level
从算法层面出发,PTM 可以帮助模型从更好的初始值开始训练:
最常见的方式为修改训练目标,即在损失函数中加上新模型与 PTM 在参数上、模型输出上或某一层的输出特征上的差异。
Heterogeneous Model Reuse
依然可以从数据、模型、算法三个角度出发:
Methods for Selecting PTMs
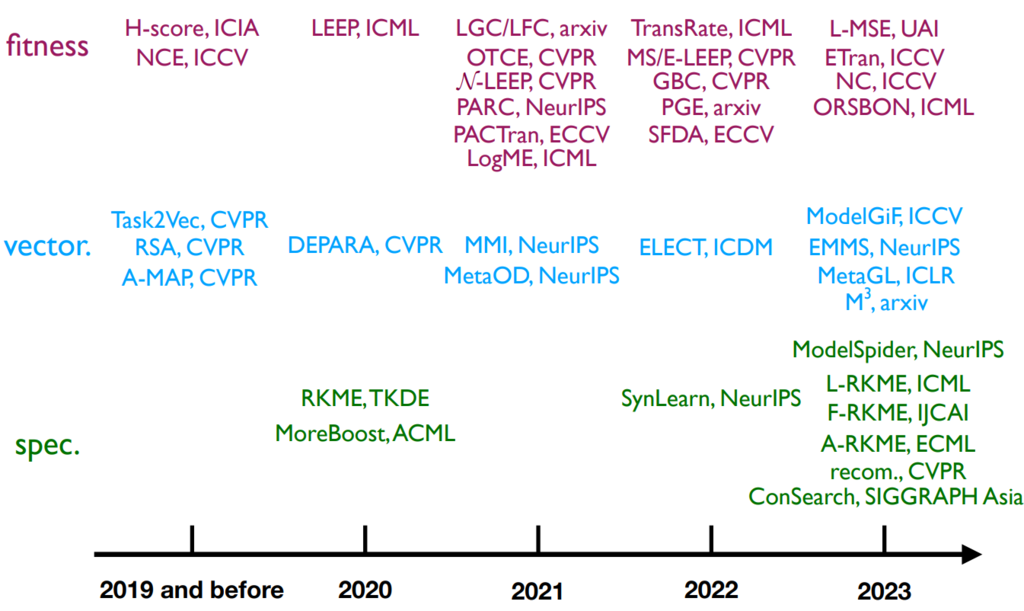
Fitness-Based Approaches
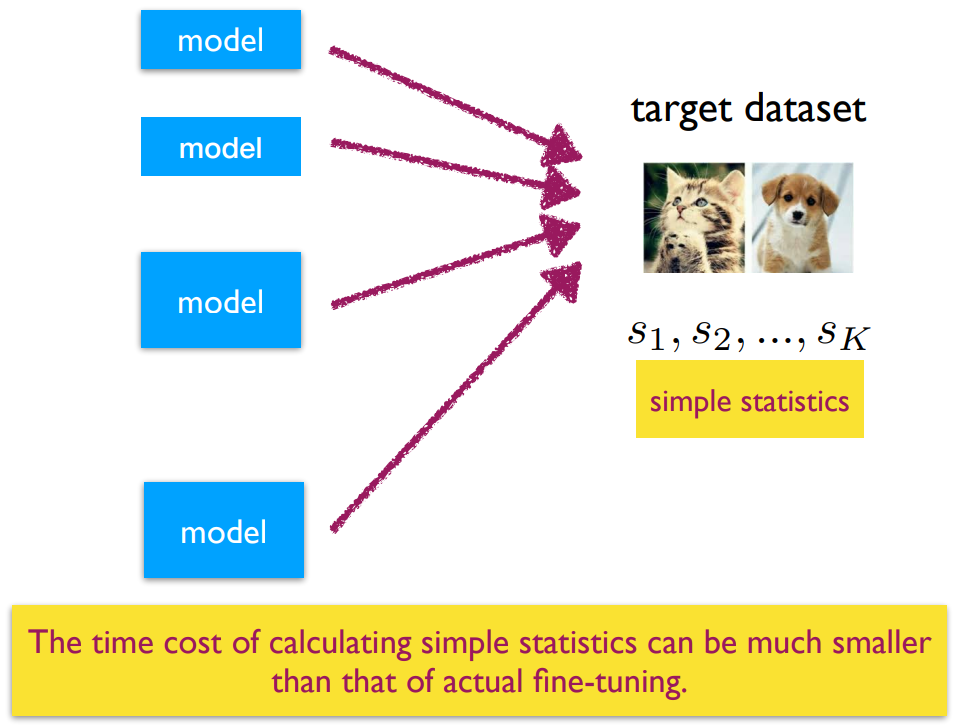
首先是第一类 fitness 方法,其根据模型在目标数据上的输出,判断模型在目标数据上的 finetune 性能(每个模型需要推理一遍数据):
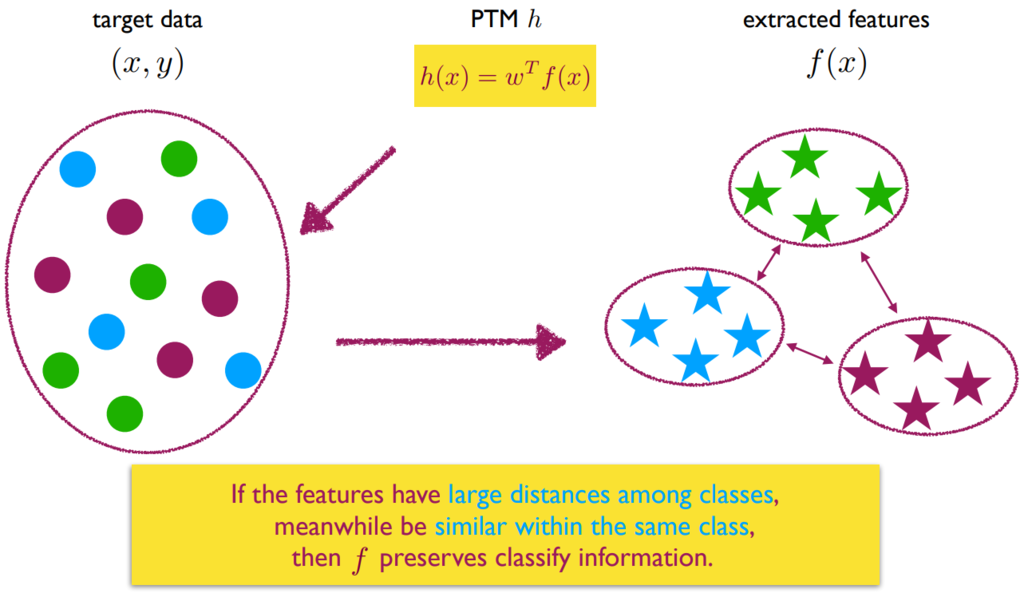
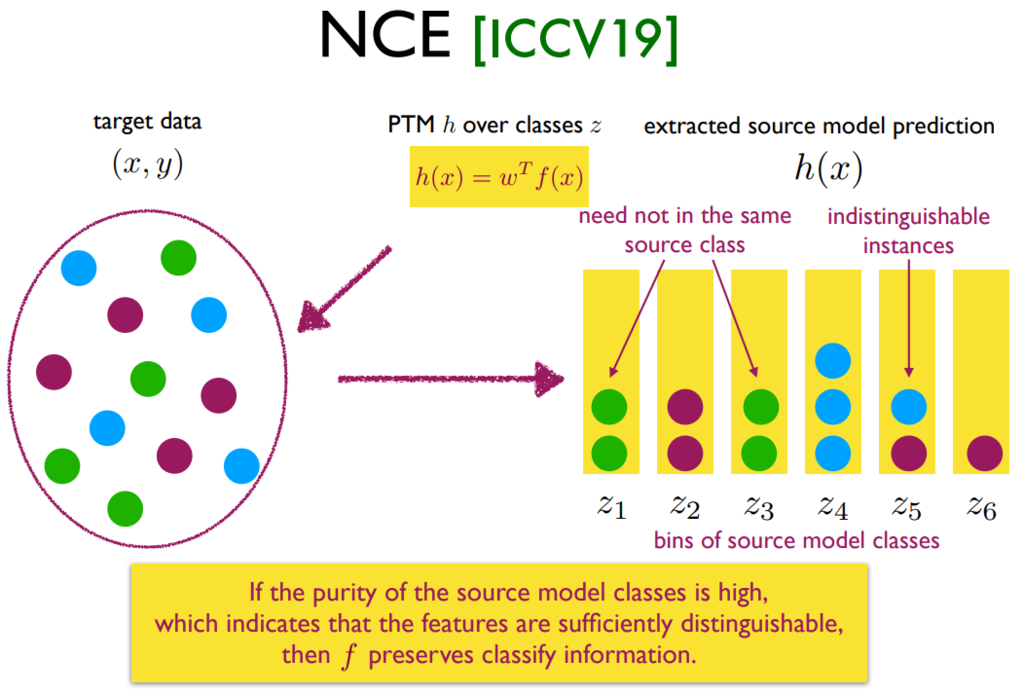
H-Score [Bao et al., ICIA’19]: 判断不同类别的数据特征(通过 PTM 提取得到),是否可以明显分开且类内比较近:

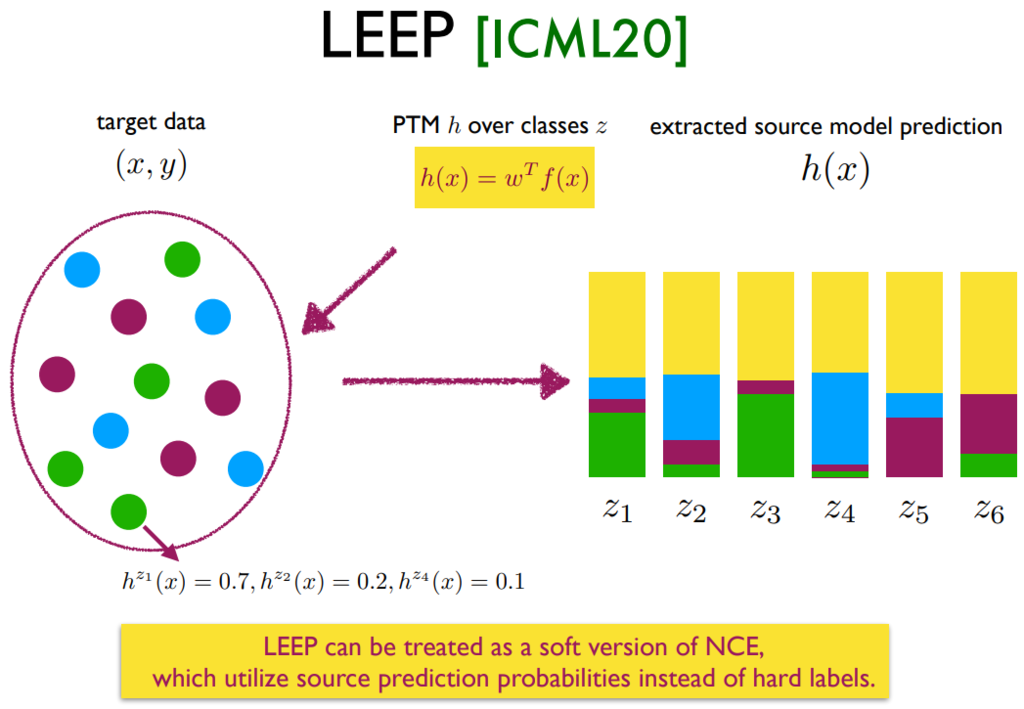
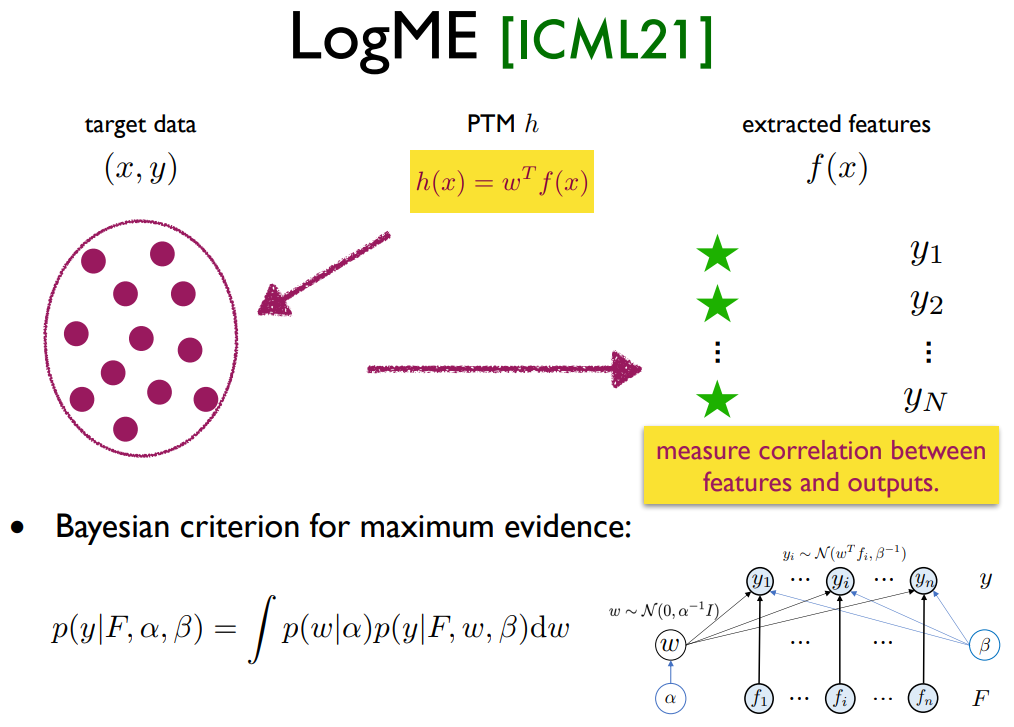
Vectorization-Based Approaches
核心困难:Build the task or model embedding space.
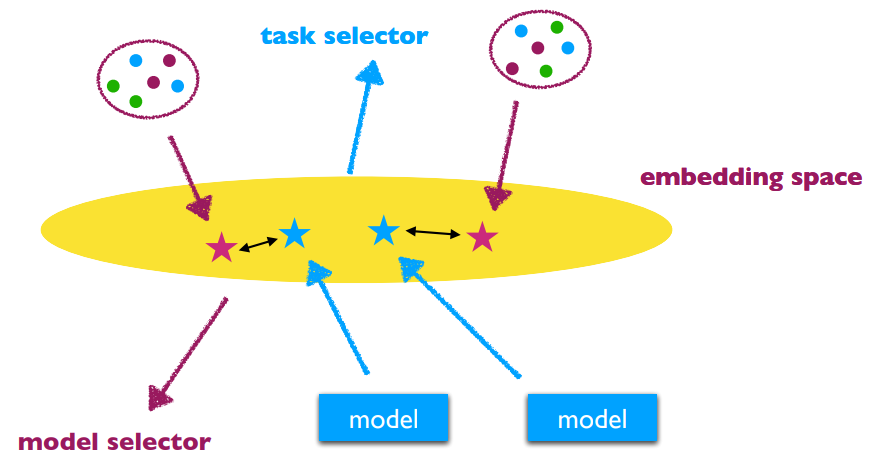
任务向量化 (Task Vectorization) 的方法:
Data similarity does not equal to task transferability.
Need more specific design of task embedding methods.